



UI 与声音设计(下)

上篇回顾戳这里:https://www.midifan.com/modulearticle-detailview-7034.htm
Multi Dimension - You are what you hear
听觉是有主观选择性的,虽然听觉系统会全盘吸收所有的信息,但人在大部分时候都会有选择地感受那些让自己感兴趣的声音。设计师要从另一个角度来考虑这个问题:在这个画面出现的时候,我希望用户听到的重点是什么?就像好莱坞流传的一个黑段子说:任何时候都要确保同一时刻不会出现三个以上的声音。意思是说,同时出现的声音类型越少,观众就越容易抓到重点、第一时间知道你想表达什么。以好莱坞的经验,三个是上限。这并不意味着说这时候只有三个声音,而是说能让你在一瞬间或者短时间里听到的重点声音只有三个,其它声音不是应该都删除,而是作为辅助和衬托的。过多的信息同时或者短时间里密集出现,只会干扰注意力和理解力。从UI设计来说,我们可以用关注度(attention)来对UI声音做一个分级,通过声音的特征区别来让用户即时了解信息的重要程度。什么样的声音会更容易引起我们的注意,这个问题在上世纪末就已经有一些研究成果了,比如说接近检波的纯人工制造声音会更容易引起我们的听觉注意力,例如各种警报声。但最近几十年,电子音乐、电子设备充斥了我们生活的方方面面之后,人工制造的声音已经逐渐变得和自然声音一样容易被忽视了。在很多硬核科幻片里,警报声已经越来越避免使用检波,检波的确不是那么悦耳,对于整体的听觉来说可能会缺乏个性、叙事性和平衡性。我也很想知道这方面的社会心理学的研究成果,然而在搜罗阅读了一批论文、书籍之后,这方面的研究非常匮乏。但从已有的理论研究上可以推导出一些规律,那也是我们在技术角度描述一个声音特征或者音色Timbre的主要方法:
- Pitch音高
- ADSR包络
- Loudness响度
- Repeat重复
Pitch“音高”的观念本身是非常模糊的一种大脑意识反应,有些人很敏锐,有些人就很迟钝。对于“音乐性”比较强的声音,我们或许会比较容易对此产生音高判断,那样的声音通常更接近人工制造的声音:基频和谐波在频率有整数倍的关系,就是所谓的“乐音”(反之就是音乐意义上的“噪声”)。但对于打击乐器,即便是定音鼓,很多人可能就无法像听钢琴那样快速反应过来它的音高,更不谈其它打击乐了。自然世界里,几乎很少有“乐音”存在,绝大部分都是“噪声”,这是物理上的定义。但这只是一种归类和定义的方法,尤其对于声音设计师来说更不应该是一种定义的“界限”。其实很多噪声也是有基频的,在技术上,通常是指音量最高的那个频段。Pitch作为一个相对量,依然是我们描述一个声音状态、特征的基本术语,因为在职业设计师看来,任何声音都是有音高的。
Pitch,是一个声音自身不同频段的强度比例组合所表现出来的一个特征,它表现出来的可能是亮度Brightness、饱和度Saturation、甚至是对比度Contrast。相对来说,Pitch越高更容易引起人的听觉注意力,同时它的指向性(可以理解为“方向性”)就越强。目前并没有明确的理论依据来告诉我们Pitch高到什么时候最容易引起听觉注意,因为这和每个人的生理状态、精神状态、以及客观声学环境有很大的关系。但是大部分人最敏感的频段在1000-2000Hz。也有说1000-4000的,但大部分专著都认可1000-2000范围。于我个人而言,特征频段范围越小,越容易细分状态,从而有机会做进一步的处理。从另一个角度看,1000-2000Hz的提升或衰减也更容易改变它在听觉上“存在感”,同时,相对其它频段来说不需要很大的提升或衰减就能让你感觉到明显的变化。(具体更多知识,请学习“等响度曲线”相关的文章或书籍,这是心理声学和应用技术中至关重要的知识点。)
同时,我们也应该注意到低频的作用。自然状态下,低频往往意味着危险和情绪压力。因为地震、雷声、建筑摇晃、大型动物的脚步和嗓音会表现出明显的大低频。快速、强烈的低频在生理上就会促进肾上腺素的产生,长期的低频刺激甚至会造成内分泌系统的紊乱。低频的另一个特点是指向性模糊,当然,这也是相对高频而言。在技术上,通常把低于70或者80Hz的频段划为低频,但也有把100Hz作为分界的。有些音乐录音师、混音师则把40或42Hz作为低切的频点,这也是很多话筒和录音设备的低切设置点。这没有明确的所谓标准划分。但在UI声音设计里,绝大部分UI声音都不会采用强烈的低频,低频的谨慎分布通常都是为了引起你的注意或者强调某些色彩特征。这一方面是习惯,因为传统电子设备上无法表现低频,比如说大部分智能手机扬声器在200Hz以下衰减非常严重,那是硬件限制。另一方面,连续强烈的低频会导致“狼来了”的结局。但在某些情况下,合适的低频会让人产生“酷”的感觉,大部分时候,这个效果取决于Right Time & Right Place原则。[关于频段的划分指称,不建议初学者纠结具体数字定义,那是没有意义的,都是相对量和习惯,更多是为了描述方便而已。]
ADSR: Attack, Decay, Sustain, Release。这是描述一个“自然产生”的声音从出现到消失在你耳朵里的四个物理阶段。

Attack:
声源从开始震动到震幅峰值的时间长度。[理论初学者请注意:这四个阶段都是时间值。和声音大小无关,都是时域描述(我在努力学习学术化)]。Attack的时间越短,不仅仅意味着它出现地非常快,也意味着我们通常说的“音头”是不是明确。打击乐器的Attack时间要比弹拨乐器快很多,它的音头就会显得比较明确,也会让你感觉很“硬”。大部分传统打击乐器的Attack频段在3500-4500Hz的范围,弱化它就可以让它显得比较“软”或者柔和。“硬”的声音相对来说更容易引起我们的注意,这也是听觉心理保护机制的一部分,很多时候它意味着“意外”和“突然”。但如果是一个长期在大噪声环境里生活的人,这样的情况在TA的听觉预警机制里就会变得疲软。不仅仅如此,Attack部分的声音特征几乎是决定性地影响你对这个声音的特征的判断和印象(或者说感觉)。这里的“特征”包括材质感、亮度、响度等很多因素,哪怕它只有几十毫秒。这是心理声学中“先入为主”效应的典型体现:对于大部分声音来说,Attack的听感特征决定了你对这个声音最初的整体印象。
Decay:
一个自然产生的声音在震动达到峰值之后,就会开始衰减。同样的Attack时间,Decay的持续时间越短、幅度越大,它让人感受到的音头存在感就越明确,即使在连续密集出现的时候,它也会让人感觉“颗粒”感的明确。但是它的衰减幅度并不取决于它自己,而是Sustain。
Sustain:
一个自然产生的声音在经过Decay衰减之后,衰减的速度会减缓、甚至震动还会相对稳定延续一段时间。Sustain的作用,在听觉感受上可以改变Attack阶段带来的先入为主的偏见,如果持续时候够长的话。但它最重要的作用是能够改变一个声音的响度(无论在技术上还是听觉上)。举个例子,枪声。真实状态下,枪声其实持续时间非常非常短,就跟爆豆子差不多。但你在边上依然会感觉很响,因为它的Attack时间可能不到5毫秒,并且Attack的峰值可以高达140dB。Decay的时间非常短,加上几乎为零的Sustain时间,前三个阶加在一起,可能还没有你拍一下巴掌的时间长。这样的声音如果真的写实性出现,你可能只会听到10毫秒的巨大声音,随后瞬间被音乐或者其他声音掩盖掉,听起来就和Glitch坏码噪声一样。但是它会引起你的注意,不是因为它足够大声,不过更多的是你无法判断这个声音是什么。如果我们要让听众听清楚,就必须提高Sustain的音量或者时长,那可以有效改变一个声音的响度,以避免它被其他声音遮掩掉。
Release:
是指一个声源停止震动后,声波在空气中扩散并且消失的时间。在餐厅里拍一下巴掌,这个声音觉得长,是因为它的Reverb。Reverb来自障碍物对声波的反射、折射,空气也会折射和反射声波。以枪声为例,我们印象中的枪声,在时间线上其实主要是Release阶段。Release改变了枪声的延续时长,从而改变了它的响度。这也是很多游戏和影视作品的处理方法。
Loudness响度:
响度是一个复杂的听觉感受,并且有相当大的主观性。(关于声音的RMS、等响度曲线、以及响度测量和响度表,请去阅读相关书籍。)但我们已经知道Attack部分的改变会轻易改变我们对响度的感觉,而不是一味地提升它的整体音量。同样,Sustain和Release也可以如此处理。然而,传统理论认为响度并不能有效地引起你的注意力,真正能够引起注意力的是足够的 “动态”。突然出现的大响度声音只是surprise你,而要surprise一个人的听觉可以有更好的方法。甚至响度在听觉记忆里的留存度也是非常低的,响度的提升更多的是能够带来的是听清楚更多内容,而过大的响度反而只会模糊内容本身所传达的信息,因为那导致了整体失真,而失真只会模糊和扭曲声音所传达的信息。
“动态”,在技术上是指一个声音的最小电平和最大电平之间的范围。安静的办公室通常50 dBSPL的声压,如果突然有东西从桌上掉下去,产生了80dBSPL的声压,那么动态范围就会有30dB,这样的动态就可能会引起你的注意。但在实际操作中,尤其是声音制作过程里,“动态”包含了音量范围和时间的关系:
- Attack的时间和峰值比例。时间越短、峰值越高,动态就越大。
- 峰值和Sustain、Release的差值、以及过程所需要的时间。落差时间(decay)越短、差值越大,动态就越大。
所以,如果出现连续的大声音,并不表示动态加大,而只是响度增加了,并且你的注意力也会随响度持续而减弱,而大动态的体验和感觉需要一定的时间间隔才能起作用。
除此以外,频率在时间和频宽范围上的变化,也会引起对“动态”感觉的变化。最常见的例子是Kick Drum和Snare所形成的节奏关系。两者的主要能量频段形成了鲜明的对比度,这是导致“动态”感觉的主要因素。动态,往往是需要一些参照物来衬托才能产生的。需要注意的是,一个比较响的声音随后紧接着一个比较轻的声音,那么很可能会听不清楚这个较轻的声音,这是听觉遮掩效应的一种情况。它们之间的间隔时间越长,遮掩效应就越轻。如果不能通过时间间隔来解决,那么只能通过提高后来者的音量来解决,当然,也可以通过立体声镜像Stereo Image差异或者主频率差的方式来缓解。如果轻的在前、响的在后,那么就可以增强后者的响度感觉。
[在声音专业领域,“动态”这个词几乎只用于音量的变化范围。如果用于描述频率和其它,一定会加上定语。]
Repeat重复:
这是一个能够引起注意的常见方法,想想各种警报声。但它更多的是帮助听觉记忆。有很多广告总是会恶形恶状地简单重复一句Slogan迫使你记住产品,这在有些国家和地区是受到严格限制的,那是典型的强迫式洗脑方式。UI声音往往也会高频次的重复出现,这种情形很容易导致听觉疲劳,这个疲劳是心理上的。就像你老母亲跟你唠叨多了,你会烦,然后你会选择性地听不见一样。所以大部分UI声音会偏轻一点,希望以此减缓听觉疲劳。这只是最常见的一种方法。我们知道现代流行音乐的一大特征就是节奏性的重复,其中最典型的Drum Kit。前文介绍过,一首歌里Drum Kit的音色并不多,但是每件乐器频率的对比度非常高,这是形成丰富节奏的基础之一,而节奏性的变化不太容易让人觉得腻味,甚至还可以产生一些乐趣。我们在设计UI声音的时候,需要能够归纳出操作体验的线条,因为大部分UI菜单的先后顺序是有某些规律的,我们就有机会让这些声音产生一些节奏感。它可以是频率对比、也可以色彩对比、甚至是更复杂的对比。大脑会把这些看起来无关、甚至各为其主的声音串联起来,形成一个节奏感的体验。不过,节奏感的问题,因人而异,有些人的节奏感会比较好,那TA很快就能接到这个梗,有些人则不然。
除了前面提到的Pitch、ADSR、Loudness和Repeat以外,另有一个特殊的状态、或者说体验特征,也是非常关键的,那就是Fresh,新鲜感。
Fresh:
新鲜的听觉很容易捕获人的注意力。然而“新鲜”在听觉这里是个很玄幻的词。它主要包含两种情况:不太熟悉的声音;出乎意料出现的声音。如果你已经理解了上文,那么应该知道一个声音对一个人来说是否“新鲜”,首先取决于他的大脑里是否存储过这个声音的特征信息。这对一个用户来说恐怕不是太大的问题,但是对职业设计师来说是个大问题。每天可能要听成百上千的声音,他们一周听的声音丰富性可能比很多人一年积累的都多,对他们来说已经很难判别哪些声音是“新鲜”的。其实,如果你(如果你是设计师或者在设计师的道路上)时刻清楚一个道理即可:如果你觉得新鲜的,那么大部分人可能会觉得新鲜;如果别人没有感受到你的用意,那么就是你没做到位。
其次,你需要对不同的受众群在听觉上有什么共识有尽可能多的了解。一些专业书籍和文章里把这种声音称为Iconic,符号化的、标志性的。Iconic Sound很容易被识别到,当它与视觉配合的时候可以产生很好的听觉记忆性。换句话说,Iconic声音会有一个明确的指代对象。它可能不会引起你的新鲜感,但它能唤起你的记忆。另外一种称为“Symbolic”,象征性的。象征性的声音在每个产品里几乎都需要考虑的,可以采用“直译”,也可以用“意译”的方式来表征某个对象,而这个对象可以是具象的人、道具、景致,也可以是一个抽象的概念或者情感。但无论如何,象征性的声音需要和对象能够建立一个合理的听觉联结。这就微妙了,可能不是所有人都能建立同样的联结。比如说雨声和水声,你很难把两者混为一谈,因为两者的特征差异很明显。但在Foley棚里,Foley Artist非常轻易地就可以用一把洒水壶把你给忽悠了。从观众的角度讲,他们不需要知道你幕后的故事,但他们至少会希望在看到雨的时候听到的雨声和画面、TA的生活经验吻合,让大脑能够顺畅建立一种体验的联结。在动画片、科幻片里,这样的象征性手法用的非常普遍,不同角色需要给一个不同特征的音色来表现,但它需要足够的重复才会产生联结作用,这就提高了学习成本。如果联结关系成功建立,那么就可能产生很明显的新鲜感,并且在记忆里建立听觉谱系。这种手法往往也是创造一个Iconic Sound的开始。UI声音设计在很大程度上是有意无意地从象征手法入手的,但要让它变成一个Iconic的,恐怕不那么容易,也是因为出现频次问题,当然也有像征手法本身的一些局限性。第三,新鲜感很多时候是来自出其不意的恰当。无论是象征性的声音、还是具象叙事性的声音,只要能达到出人意料的效果,那么就可以产生新鲜感,即使这个声音单独听起来平淡无奇。越是为人熟悉的声音,越容易被忽略,也越难创造出新的联结关系,因为已有的联接关系可能已经很稳固。这一点,往往不是哪本书或者哪个老师能够教出来的,这取决于设计师自身对产品的理解深度以及表达能力,外加一些运气。
Mix of the dimensions
为了方便笔记,这里做一个汇总。
所以,无论哪种听觉“共识”,都是需要学习成本的。
从整体布局到定位一套UI的每个具体声音,再一次提炼和简化为4个思考点:
- 性质分类
- 作用分类
- 含义表达
- 具体功能
理解UI的声音
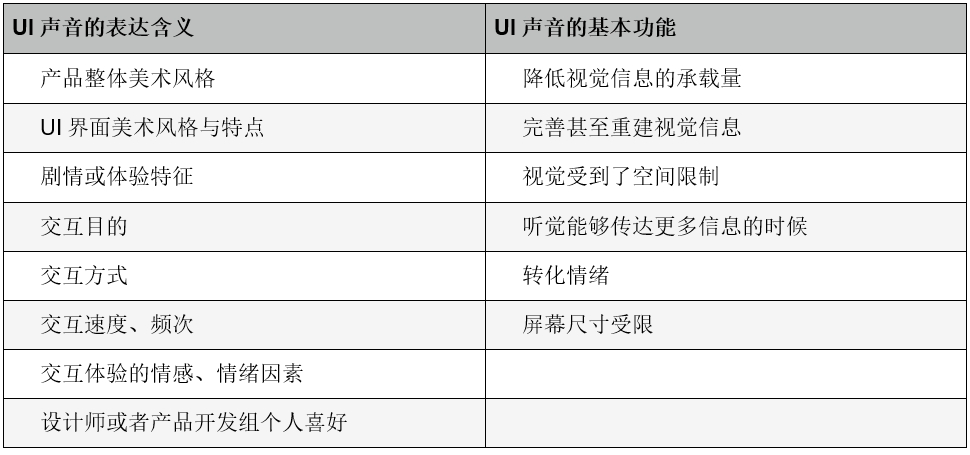
UI声音的基本分类法
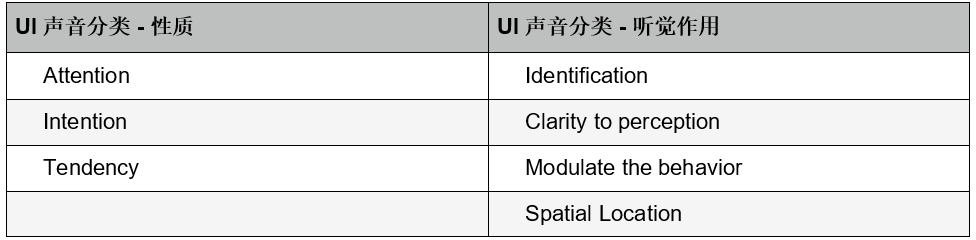
影响一个UI声音特征的因素
- Pitch音高
- ADSR包络
- Loudness响度
- Repeat重复
- Fresh
其他关键词:
- 听觉记忆
- 听觉学习成本
- Remapping 布局
- Timbre 音色
- Pattern 表现模式
- Hearing Imagine & Connection 听觉联结
- Hearing Context 听觉语境
为了帮助理解和记忆,这里有一张简单的示意图作为举例:

这张图只是一个简单的例子,对UI声音的不同可能性做了一个简单分类归纳,分别是Intengtion、Emotion和Tendency三个维度。对于项目里的每个UI声音或者每一组UI声音,都可以通过这样的或者其他方式给他们做一个直观的设定,来确定基本的布局是否合理。其中的每一根轴,都可以按照自己的习惯、项目的情况做不同的定义,比如说信息的重要等级也可以作为一根轴、不同UI的音高可以是另一根轴。这种方法只是一个快速的分类法,并不需要特别精确。如果你有强迫症,也可以按 |-10 — 0 — +10|作为刻度。
Dimension - Life in Future
目前有很多大学实验室和商业公司的实验室都在研究和预测未来50年我们的数字化生活会变成什么样子、交互界面会有怎样的不同。其实那都是猜测,究竟有多少会变成现实,谁也不肯定。但我们多少还是可以预测出一些基本的情况。
Smart Adaptive UI Sound
智能主动适配性的UI声音系统,它会根据你所处的环境、场景和个人习惯做出适配性的UI声音反馈,比如说音量控制、不同环境下的声音预设,例如
- Environment & Scene(家、办公室、餐馆、机场….)
- User Personality (个人听觉口味)
- Physical & Psychological period: 生理或者心理周期
系统会根据你的心情、餐馆环境和用餐对象来自动调整音量和UI声音,当然,你可能会需要一点时间来学习和适应,你也可以训练系统来了解甚至学习你的听觉习惯,以降低你的学习成本。总体来说,未来交互界面的声音会变得越来越智能化、人性化,同样的闹铃,在不同情况下可能会有不同的Pitch和ADSR、但依然能够确保你能第一时间反应过来它的意图。而不是现在这种给你什么就吃什么的被动局面。也肯定不会像那些科幻电影里一样给你各种哔哔声。
Non-touchable Interaction
非接触式的交互可能会变得越来越普及,语音、肢体语言(不仅仅是姿态,还有体温、心率等医学数据)的识别会变得越来越准确。设想一下,如果家里的很多智能化设施都可以通过语音来交互的话,那回给UI声音设计带来多少不同?或许,语言化交互会更多,因为用户学习成本可以最低。那么因此是否会导致游戏那样的产品也会有更多的语音交互界面,而不是现在主流的Non-speech UI Sound?或者是语音、非语音方式的混合,在有些论文里认为这种混合方式是效率最高、学习成本最低的。或许有道理,如果你在东京的轨道交通网里体验过,那里的广播充斥了各种经过精心设计的语音、Jingle和音效,会让陌生人即使不懂日语也能快速接收到大部分信息,并且很悦耳。
Private Hearing
我们知道,声音的传播本身是全指向的,手机里出来的声音,周围的人都能听到。私密性的聆听,这目前还是比较前沿的技术领域,它的目标是让声源发出的声音只传递给特定的人。很多实验室也在研究不同的解决方案。目前最传统和成熟的技术是骨传导。人耳只是接收了一部分从空气中传达到耳膜的那部分声波,但其实还有相当一部分是通过人体骨骼和肌肉来传导的。你可能会觉得自己的嗓子很好,但是录音之后惨不忍睹,就是因为话筒只接收了空气的震动,而没有把你身体震动捕捉下来,而你自己听到自己的声音却是包含了身体震动的。但骨传导技术的存在一些难以解决的问题,比如说频响,它直接影响了听觉体验的质量。并且,骨传导和现有的主流耳机一样,都是穿戴式设备,多少会限制应用场景。有一家以色列的公司宣称在2021年底会推出商用的产品,利用超声波的指向性,通过超声波把20-20kHz的声音信号直接传送到目标对象的大脑。这种方式在理论上是完全可行的,虽然我们还很难预判它的实际结果如何,至少,在有效距离上应该会存在一些缺陷,因为超声波的功率问题。但也因此可以看到,利用已有的成熟技术,确实是存在改变现有开放式聆听方式的办法,或许目前只是制造和生产成本问题。
未来50年里,可穿戴设备会不会成为主流?可能会是芯片植入、也可能会是更加简便的便携式设备。可预见的是,云端计算和几乎没有带宽限速的无线网络,加上充分人性化的AI设备、机器人,可能会让我们的生活变得更加便捷,因此也会导致现在基于智能手机的便携智能中心应该会以完全不同的样子出现,甚至会有更多的无接触交互,至少交互方式的限制会大大减小。在那样的情况下,语音+非语音音效的组合,或许会是那种环境下最简单直接的UI声音方向。用户甚至可以轻松地整合起来自不同厂商的的不同电子产品,并让他们出现一套系统性的、不需要每次都要学习的UI声音系统,形成个性化的整合环境。你听到的UI嗓音是能够符合你个性和口味的,能够带有人性化语气、语调的合成语音。并且音效可能并不是预制好的样本,而是“自驱动”(automated driven sound) 产生的,这方面确实已经有很多人在研究。文章开头提到的Sonification,也是其中的一种思路,它研究的是把视觉、甚至非听觉性的事件和状态转换为可以听到的声音。
结语
这篇文章基本上只是“众多”理论和实践的总结。本质上,它无法回答你的所有问题,甚至可能没有任何直接的帮助。“众多”的引号,表示这个领域其实非常狭窄,研究和试验之匮乏,导致论文之间也是充斥着相互引用。但作为凡胎设计师,尽量归纳和思考一些问题或者现象,依然是我们的职业本份。这也不是什么“方法论”,因为连理论依据都不全。在设计过程中,我们需要找到一些合适的途径来对这个产品UI部分的每个声音做一个分析和布局,形成一个有效的框架和体验线,才能让声音设计的效果真正体现出来,也让我们的职业生活变得有趣一些。为了更有效地分类和布局UI声音,你甚至可以把前文提到的一些分类关键词混合在一起处理,例如:
- Priority levels, 按重要程度分优先级
- Attention levels,按受关注程度分等级
- Emotional context:情绪性或者色彩性分布
- Mapping objective groups :目标集群的分布
找到自己的方法、找到一个项目最合适的布局,才是关键。
不同的专业书籍和文章,作者都会从自身的职业经验角度出发来描述。声音设计领域没有一本大而全的教科书,这是现状。学会从不同学科和角度理解问题、看待问题,善待理论、敬畏职业才是根本。
既然是跟声音有关的文章,我也考虑过用更多的图示、声音样本案例来加强说明。但给自己找了一个非常自洽的借口:几乎所有这种著作都没样本,甚至基本没有图示。论文倒是有很多配图和声音样本的。其实除了懒,另外一点担心是,样本的选择或许会带来一些误导。希望接下来有哪个项目上线之后,我有机会拿出样本做一个分析文章。
本文的章节名称用了一个词:Dimension。只是为了表示向学术靠拢又未遂的意思,并不代表我的本意。
知识和见解有限,文字能力浅薄,请谅解。有错误的话,麻烦不要告诉我,让我继续犯错误。
谢谢!
主要参考书目与文章:
Sound Design: The Expressive Power of Music, Voice and Sound Effects in Cinema
By David Sonnenschein
[ 声音设计领域最好的书,从声音设计角度阐述心理声学、物理声学。无论初学还是行业老手都适合。强烈推荐原版,以正确、准确地理解作者的思路,新手建议两遍以上。]
电影电视声音(Sound for Film and Television中文版)
By Tomlinson Holman , 人民邮电出版社
[用比较直观易懂的文字讲解物理声学、电声学、数字音频,以及少量心理声学。]
The Universal Sense - How hearing shapes the mind
By Seth S.Horowitz, Ph.D.
[以非常生活化的角度讲解心理声学,并且融入了一些比较新的学术研究观点。]
Auditory Interface - A Design Platform
By Dan Gardonfors
The Sonification Handbook
Edited by Thomas Hermann, Andy Hunt, John G.Neuhoff
Auditory Interface
By S.Peres, V.Best and other 6 authors
Auditory Interface
By Gaver & Bly from Buxton
Sensing the future of HCI: Touch, Taste and Smell User Interface
By Marianna Obrist, Carlos Velasco and other 6 authors
Utilizing Sound Effects in Mobile User Interface Design
By Hannu Korhonen, Jukka Hoi, Mikko Heikkinen
转载文章请注明出自 Midifan.com
